排序算法:一种能将一串数据依照特定的排序方式进行排列的一种算法。
排序算法性能:取决于时间和空间复杂度,其次还得考虑稳定性,及其适应的场景。
稳定性:让原本有相等键值的记录维持相对次序。也就是若一个排序算法是稳定的,当有俩个相等键值的记录R和S,且原本的序列中R在S前,那么排序后的列表中R应该也在S之前。
以下来总结常用的排序算法,加深对排序的理解。
排序算法目录
冒泡排序
原理
俩俩比较相邻记录的排序码,若发生逆序,则交换;有俩种方式进行冒泡,一种是先把小的冒泡到前边去,另一
种是把大的元素冒泡到后边。
性能
时间复杂度为O(N^2),空间复杂度为O(1)。排序是稳定的,排序比较次数与初始序列无关,但交换次数与初始序列有关。
优化
若初始序列就是排序好的,对于冒泡排序仍然还要比较O(N^2)次,但无交换次数。可根据这个进行优化,设置一个flag,当在一趟序列中没有发生交换,则该序列已排序好,但优化后排序的时间复杂度没有发生量级的改变。
代码
1 | void bubble_sort(int arr[], int len){ |
插入排序
原理
依次选择一个待排序的数据,插入到前边已排好序的序列中。
性能
时间复杂度为O(N^2),空间复杂度为O(1)。算法是稳定的,比较次数和交换次数都与初始序列有关。
优化
直接插入排序每次往前插入时,是按顺序依次往前找,可在这里进行优化,往前找合适的插入位置时采用二分查找的方式,即折半插入。
折半插入排序相对直接插入排序而言:平均性能更快,时间复杂度降至O(NlogN),排序是稳定的,但排序的比较次数与初始序列无关,总是需要foor(log(i))+1次排序比较。
使用场景
当数据基本有序时,采用插入排序可以明显减少数据交换和数据移动次数,进而提升排序效率。
代码
1 | void insert_sort(int arr[], int len){ |
希尔排序
原理
插入排序的改进版,是基于插入排序的以下俩点性质而提出的改进方法:
- 插入排序对几乎已排好序的数据操作时,效率很高,可以达到线性排序的效率。
- 但插入排序在每次往前插入时只能将数据移动一位,效率比较低。
所以希尔排序的思想是:
- 先是取一个合适的gap<n作为间隔,将全部元素分为gap个子序列,所有距离为gap的元素放入同一个子序列,再对每个子序列进行直接插入排序;
- 缩小间隔gap,例如去gap=ceil(gap/2),重复上述子序列划分和排序
- 直到,最后gap=1时,将所有元素放在同一个序列中进行插入排序为止。
性能
开始时,gap取值较大,子序列中的元素较少,排序速度快,克服了直接插入排序的缺点;其次,gap值逐渐变小后,虽然子序列的元素逐渐变多,但大多元素已基本有序,所以继承了直接插入排序的优点,能以近线性的速度排好序。
代码
1 | void shell_sort(int arr[], int len){ |
选择排序
原理
每次从未排序的序列中找到最小值,记录并最后存放到已排序序列的末尾
性能
时间复杂度为O(N^2),空间复杂度为O(1),排序是不稳定的(把最小值交换到已排序的末尾导致的),每次都能确定一个元素所在的最终位置,比较次数与初始序列无关。
代码
1 | void select_sort(int arr[], int len){ |
快速排序
原理
分而治之思想:
- Divide:找到基准元素pivot,将数组A[p..r]划分为A[p..pivotpos-1]和A[pivotpos+1…q],左边的元素都比基准小,右边的元素都比基准大;
- Conquer:对俩个划分的数组进行递归排序;
- Combine:因为基准的作用,使得俩个子数组就地有序,无需合并操作。
性能
快排的平均时间复杂度为O(NlogN),空间复杂度为O(logN),但最坏情况下,时间复杂度为O(N^2),空间复杂度为O(N);且排序是不稳定的,但每次都能确定一个元素所在序列中的最终位置,复杂度与初始序列有关。
优化
当初始序列是非递减序列时,快排性能下降到最坏情况,主要因为基准每次都是从最左边取得,这时每次只能排好一个元素。
所以快排的优化思路如下:
- 优化基准,不每次都从左边取,可以进行三路划分,分别取最左边,中间和最右边的中间值,再交换到最左边进行排序;或者进行随机取得待排序数组中的某一个元素,再交换到最左边,进行排序。
- 在规模较小情况下,采用直接插入排序
代码
1 | //快速排序 |
归并排序
原理
分而治之思想:
- Divide:将n个元素平均划分为各含n/2个元素的子序列;
- Conquer:递归的解决俩个规模为n/2的子问题;
- Combine:合并俩个已排序的子序列。
性能
时间复杂度总是为O(NlogN),空间复杂度也总为为O(N),算法与初始序列无关,排序是稳定的。
优化
优化思路:
- 在规模较小时,合并排序可采用直接插入;
- 在写法上,可以在生成辅助数组时,俩头小,中间大,这时不需要再在后边加俩个while循环进行判断,只需一次比完。
代码
1 | //归并排序 |
堆排序
原理
堆的性质:
- 是一棵完全二叉树
- 每个节点的值都大于或等于其子节点的值,为最大堆;反之为最小堆。
堆排序思想:
- 将待排序的序列构造成一个最大堆,此时序列的最大值为根节点
- 依次将根节点与待排序序列的最后一个元素交换
- 再维护从根节点到该元素的前一个节点为最大堆,如此往复,最终得到一个递增序列
性能
时间复杂度为O(NlogN),空间复杂度为O(1),因为利用的排序空间仍然是初始的序列,并未开辟新空间。算法是不稳定的,与初始序列无关。
使用场景
想知道最大值或最小值时,比如优先级队列,作业调度等场景。
代码
1 | void shiftDown(int arr[], int start, int end){ |
计数排序
原理
先把每个元素的出现次数算出来,然后算出该元素所在最终排好序列中的绝对位置(最终位置),再依次把初始序列中的元素,根据该元素所在最终的绝对位置移到排序数组中。
性能
时间复杂度为O(N+K),空间复杂度为O(N+K),算法是稳定的,与初始序列无关,不需要进行比较就能排好序的算法。
使用场景
算法只能使用在已知序列中的元素在0-k之间,且要求排序的复杂度在线性效率上。
代码
1 | //计数排序 |
桶排序
原理
- 根据待排序列元素的大小范围,均匀独立的划分M个桶
- 将N个输入元素分布到各个桶中去
- 再对各个桶中的元素进行排序
- 此时再按次序把各桶中的元素列出来即是已排序好的。
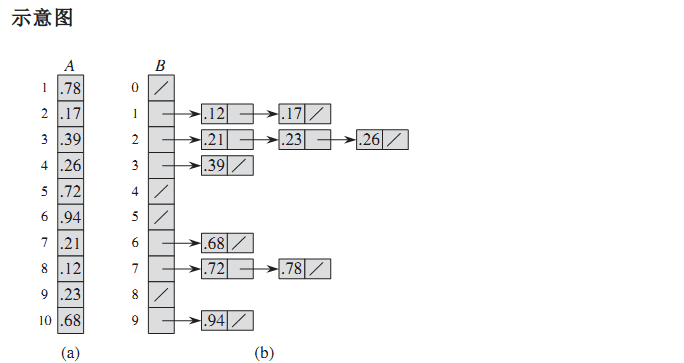
性能
时间复杂度为O(N+C),O(C)=O(M(N/M)log(N/M))=O(NlogN-NlogM),空间复杂度为O(N+M),算法是稳定的,且与初始序列无关。
使用场景
算法思想和散列中的开散列法差不多,当冲突时放入同一个桶中;可应用于数据量分布比较均匀,或比较侧重于区间数量时。
基数排序
原理
对于有d个关键字时,可以分别按关键字进行排序。有俩种方法:

总结
以上排序算法的时间、空间与稳定性的总结如下:
| Algorithm | Average | Best | Worst | extra space | stable |
|---|---|---|---|---|---|
| 冒泡排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 直接插入排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 折半插入排序 | O(NlogN) | O(NlogN) | O(N^2) | O(1) | 稳定 |
| 简单选择排序 | O(N^2) | O(N^2) | O(N^2) | O(1) | 不稳定 |
| 快速排序 | O(NlogN) | O(NlogN) | O(N^2) | O(logN)~O(N^2) | 不稳定 |
| 归并排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(N) | 稳定 |
| 堆排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(1) | 不稳定 |
| 计数排序 | O(d*(N+K)) | O(d*(N+K)) | O(d*(N+K)) | O(d*(N+K)) | 稳定 |
